Stop Saying RAG Is Dead
I’m tired of hearing “RAG is dead.” That’s why Ben Clavié and I put together this open 7-part series to discuss why RAG is not dead, and what the future of RAG looks like.
The oversimplified version from 2023 deserves the criticism: chuck documents into a vector database, do cosine similarity, call it a day. That approach fails because compressing entire documents into single vectors loses critical information. But retrieval itself is more important than ever. LLMs are frozen at training time. Million-token context windows don’t change the economics of stuffing everything into every query.
What We Learned
We started by questioning how we measure success. Nandan Thakur showed that traditional IR metrics optimize for finding the #1 result. RAG needs different goals: coverage (getting all the facts), diversity (corroborating facts), and relevance. Models that ace BEIR benchmarks often fail at real RAG tasks.
From there, we explored how retrieval can reason. Orion Weller’s models understand instructions like “find documents about data privacy using metaphors.” His Rank1 system generates explicit reasoning traces about relevance, surfacing documents that traditional systems never find.
Antoine Chaffin then showed why single vectors lose information. Late-interaction models like ColBERT preserve token-level detail instead of forcing everything into one conflicted representation. The result: 150M parameter models outperforming 7B parameter alternatives on reasoning tasks.
Bryan Bischof and Ayush Chaurasia made the case for multiple representations. Their art search demo finds the same painting through literal descriptions, poetic interpretations, or similar images, each using different indices. Stop searching for the perfect embedding. Build specialized representations and route intelligently.
Kelly Hong’s research on “Context Rot” revealed that LLM performance degrades significantly as input length increases, even on simple tasks. Semantic matching, distractors, and irrelevant information cause failures that lexical benchmarks like “needle in a haystack” miss entirely. Thoughtful retrieval and context engineering beat dumping everything into the prompt.
Finally, Jo Kristian Bergum reminded us that sophistication isn’t complexity. You don’t need a graph database for GraphRAG. A CSV or Postgres works fine. Vector search already uses graphs (HNSW), so you can do graph-like retrieval without new infrastructure.
Each talk is covered in more detail below.
Annotated Notes From the Series
Each post includes timestamped annotations of slides, saving you hours of video watching. We’ve highlighted the most important bits and provided context for quickly grokking the material.
| Title | Description | |
|---|---|---|
 |
Part 1: I don’t use RAG, I just retrieve documents | Ben Clavié explains why naive single-vector search is dead, not RAG itself |
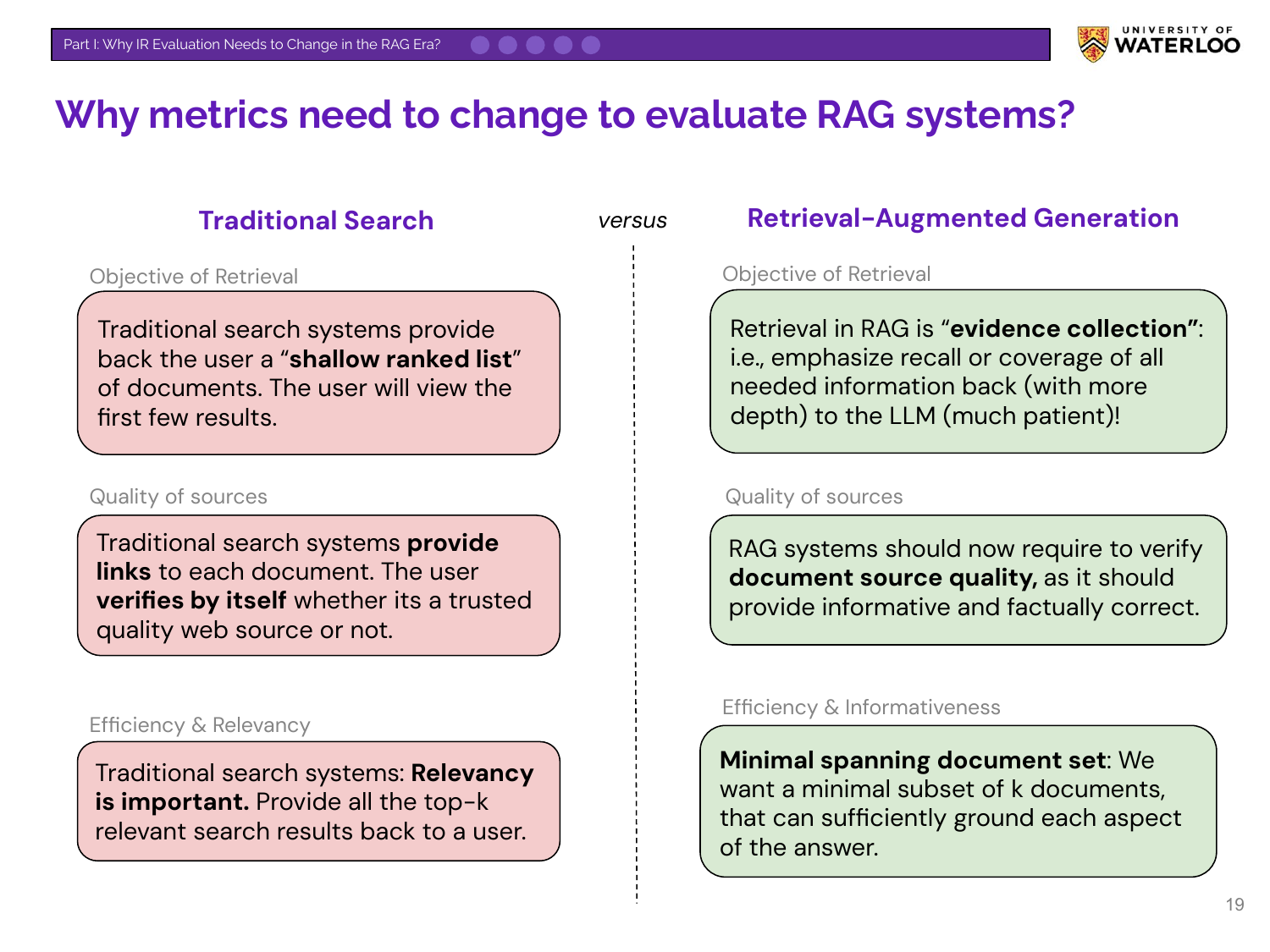 |
Part 2: Modern IR Evals For RAG | Nandan Thakur shows why traditional IR metrics fail for RAG and introduces FreshStack |
 |
Part 3: Optimizing Retrieval with Reasoning Models | Orion Weller demonstrates retrievers that understand instructions and reason about relevance |
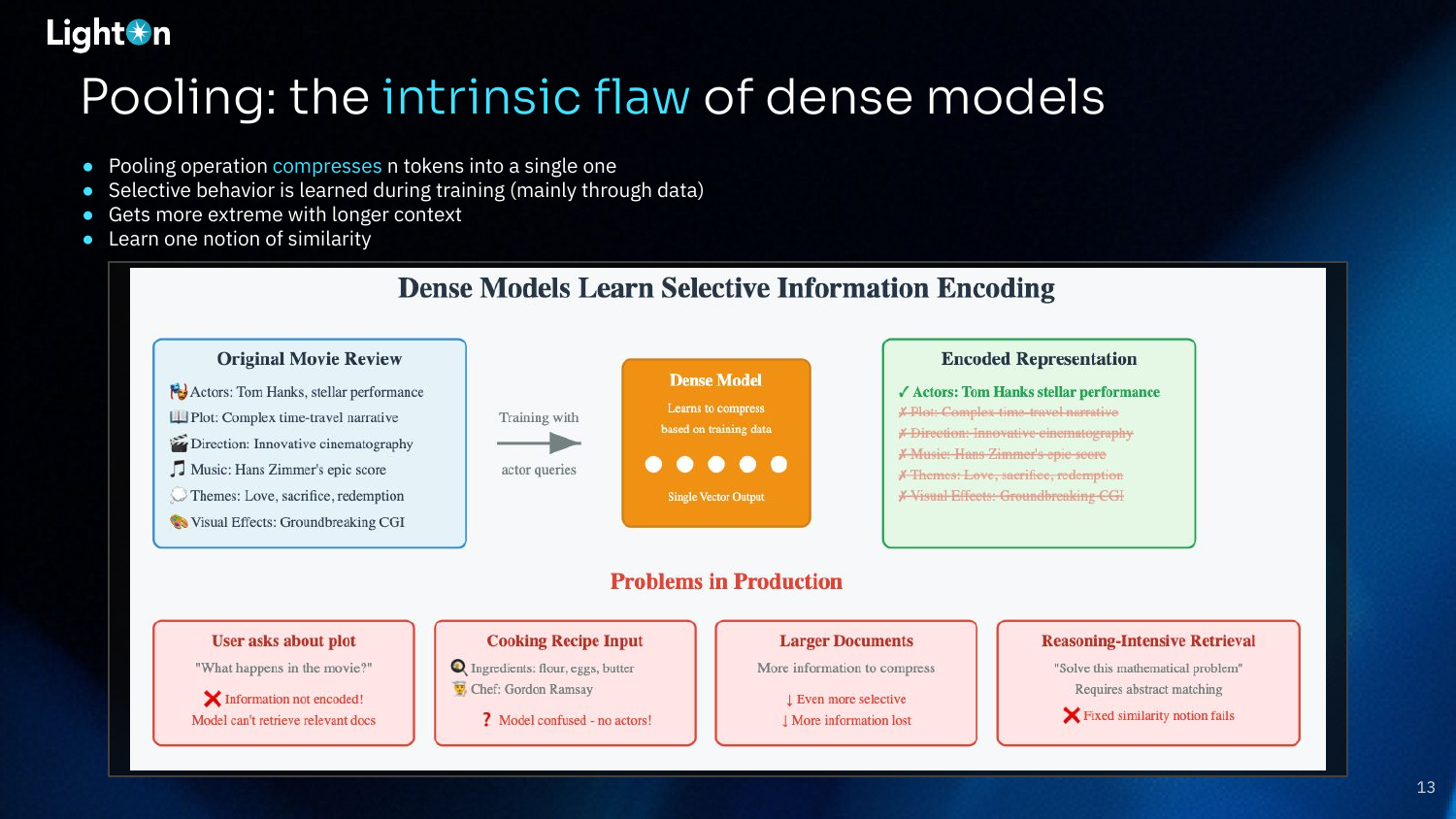 |
Part 4: Late Interaction Models For RAG | Antoine Chaffin reveals how ColBERT-style models preserve information that single vectors lose |
 |
Part 5: RAG with Multiple Representations | Bryan Bischof and Ayush Chaurasia show why multiple specialized indices beat one perfect embedding |
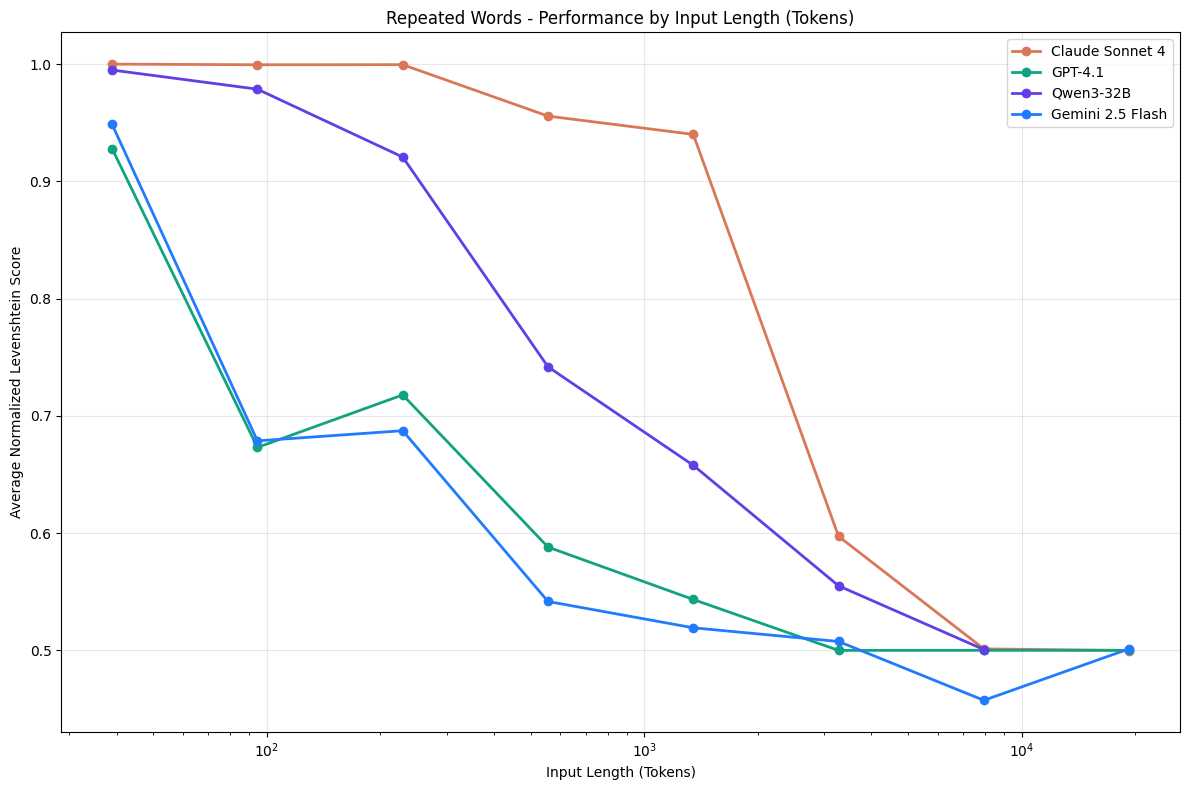 |
Part 6: Context Rot | Kelly Hong explains how LLM performance degrades with longer inputs and why context engineering is critical |
 |
Part 7: You Don’t Need a Graph DB (Probably) | Jo Kristian Bergum explains why graph databases are usually overkill for RAG |
PDF Version
A PDF version of the series is available here.