P7: You Don’t Need a Graph DB (Probably)
Every so often, a technology captures the industry’s attention. Graph databases are having their turn, fueled by a desire to have a powerful way to augment LLMs with your data. The logic seems simple: if your data is connected, you need a graph.
Throughout this series, we’ve argued that naive single-vector RAG is dead and shown more sophisticated approaches: better evals, reasoning, late interaction and multiple representations. But sophistication isn’t the same as complexity. There’s no better example of unnecessary complexity than reaching for a graph database before you’ve exhausted simpler options.
That’s why I hosted a talk with Jo Kristian Bergum. Jo is a 25-year veteran in search and retrieval, with experience at Yahoo and Vespa. He’s one of the few who publicly shares this skepticism.
Jo covers when graph databases are overkill and when they make sense.
Below is an annotated version of his presentation.
👉 These are the kinds of things we cover in our AI Evals course. You can learn more about the course here. 👈
 (
(The Hunt for a Silver Bullet
Interest in RAG has exploded since late 2022. More engineers than ever are tackling search problems. But this led to a frantic search for a silver bullet.
First, it was the specialized vector database. Now, with the popularity of a Microsoft paper on “GraphRAG,” the pendulum is swinging toward graph databases.
Jo argues this is flawed thinking. There is no single tool that will solve all your problems. The desire to map a new technique (GraphRAG) to a technology (a graph DB) is a trap many engineers fall into.
 (
(Do You Even Need RAG?
Before we get to graphs: do you need a retrieval component?
The “R” in RAG stands for retrieval. The classic information retrieval (IR) model involves a user with an information need, a query, a retrieval system, and a ranked list of documents.
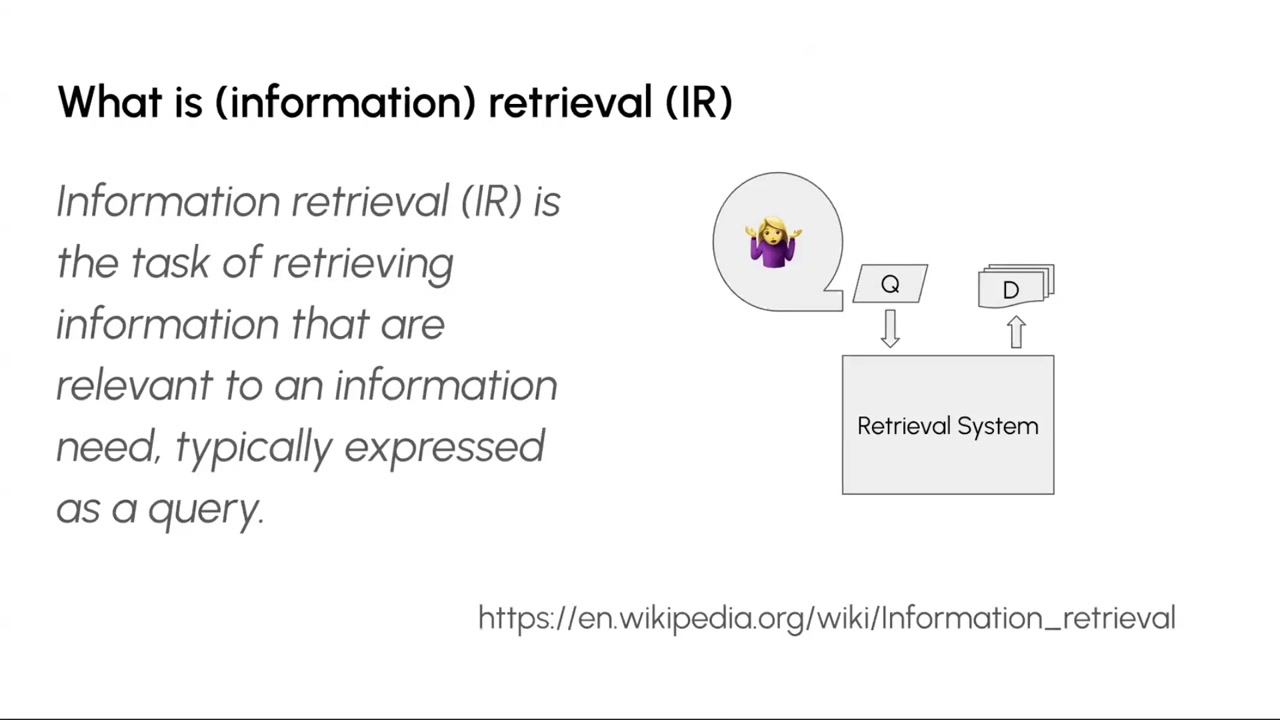 (
(When LLMs had tiny 8k context windows, retrieval was a necessity. But now, models like Gemini can handle 1 million tokens. That’s about 3 megabytes of raw text, the equivalent of an old floppy disk.
 (
(Jo shared an anecdote about a company struggling with a complex RAG pipeline. When he asked how many documents they had, the answer was 300. For that scale, he advised them to feed all the documents into the LLM’s context window. It was simpler, cheaper, and more effective than over-engineering a retrieval stack.
If your document set is small enough and your query volume is low, stuffing the context window is a valid strategy.
This connects to Kelly Hong’s research on context rot (Part 6). Her experiments showed that LLM performance degrades with distractors (documents that are similar but contain different information). When your documents cover distinct topics with little overlap, you sidestep this problem. Few distractors means less context rot.
But most real-world corpora don’t look like this. They have overlapping content, similar documents, and scale beyond what fits in context. That’s when retrieval becomes essential.
Deconstructing GraphRAG
So what is this “GraphRAG” that’s causing all the fuss? The technique, as described in the Microsoft paper, involves a few steps:
- Process the corpus: Use an LLM to read your entire document collection. This is an expensive, offline process.
- Build a knowledge graph: Prompt the LLM to extract entities (nodes) and relationships between them (edges).
- Query the graph: At query time, traverse this graph to find relevant information.
The challenge is building and maintaining the graph. A knowledge graph is a collection of triplets: (source_entity, relationship, target_entity). You can store this in a CSV file, a JSON object, or a standard relational database like Postgres.
 (
(The hard part is keeping everything accurate. That means either spending tokens on LLM calls, or getting domain experts to help.
Evaluation
How do you know if adding a knowledge graph, or any new technique, is improving your results? You have to measure it.
This is the step most teams skip. They jump from one new method to the next without a stable benchmark. As Nandan showed in Part 2, you need an evaluation framework before you can make good decisions about retrieval techniques. In retrieval, we use metrics like:
- Mean Reciprocal Rank (MRR): Measures how high up the list the first relevant document appears.
- Precision: Of the documents you returned, how many were relevant?
- Recall: Of all possible relevant documents, how many did you find?
To use these metrics, you need an evaluation dataset. This involves taking a sample of real user queries and manually labeling which documents are relevant for each query. This “golden dataset” is your ground truth. It allows you to compare retrieval methods and know if a change is an improvement.
 (
(When to Use a Graph Database
Once you have an evaluation framework, you can start asking the right questions. A specialized graph database (like Neo4j) is optimized for fast traversal of graph structures, usually by keeping the graph in memory.
Before you add one to your stack, ask yourself:
- Do I need fast, low-latency graph traversal?
- Is my graph so large that a simpler solution (like Postgres or a file) is too slow?
- Does my use case require complex, multi-hop queries (e.g., finding friends of friends of friends)?
If the answer to these questions isn’t a clear “yes,” you probably don’t need a specialized graph DB. The operational complexity and cost of adding another database to your stack is high. As Jo pointed out, early Facebook ran its massive social graph on MySQL. You can get surprisingly far with general-purpose tools.
 (
(Key Takeaways
In this series, we’ve shown you how to move beyond naive RAG: better evals, reasoning, late interaction, multiple representations, context engineering. But the goal was never complexity for its own sake.
Jo’s talk reinforces this. There is no silver bullet. Before you adopt a new method like GraphRAG, build a golden dataset to measure if it improves performance (Part 2). You don’t need special tools. A knowledge graph can live in a CSV file or Postgres. Early Facebook ran their social graph on MySQL. Vector search algorithms like HNSW are already graph-based, so you can implement graph-like retrieval strategies without adding new infrastructure.
👉 These are the kinds of things we cover in our AI Evals course. You can learn more about the course here. 👈
Video
Here is the full video: