P5: RAG with Multiple Representations
As part of our LLM Evals course, I hosted Bryan Bischof and Ayush Chaurasia for the final part of our 5-part mini-series on evaluating and optimizing RAG. They argued that effective retrieval lies not in finding a single, perfect data representation, but in creating and leveraging multiple, diverse representations with a router to better serve user intent, a concept they demonstrate with semantic dot art.
Below is an annotated version of their presentation, with timestamped links for each slide.
👉 These are the kinds of things we cover in our AI Evals course. You can learn more about the course here. 👈
Annotated Presentation
The Map is Not the Territory

The presentation’s central theme is that a “map” (a data representation) is not the same as the “territory” (the real-world data). In machine learning, this distinction is an advantage. Models and embeddings are our maps, and we can create many different maps of the same territory to serve different purposes.
Deconstructing RAG Buzzwords
The RAG landscape is filled with terms that can obscure fundamental principles. These terms can be deconstructed into simpler concepts.
Naive RAG is better understood as Simple RAG: the foundational approach of searching a vector store with a vector to find similar items.
Agentic RAG involves an LLM choosing how to search, giving the impression that the model can remove the engineer from designing the retrieval pipeline.

Hybrid RAG combines Simple RAG with classic retrieval techniques like keyword matching, allowing for searches with multiple signals simultaneously.

Graph RAG uses the relationships between objects to improve retrieval, such as identifying stores that sell “home goods” to find a coffee filter, also considering proximity.

Multi-Modal RAG has two meanings: searching with multiple data types (text and images) or searching across multiple locations (“modes”) within the same latent space for a single item.

All these techniques are different approaches to the same problem and could have been invented from first principles.
A First-Principles View of RAG
Advanced RAG techniques can be reframed as core engineering pipelines.

Hypothetical Document Embeddings (HyDE) is a document enrichment pipeline. It uses an LLM to rewrite documents into the language that users are likely to search with. A dense, technical document can be rewritten into a simpler description, creating a new, more searchable “map” of the original.
Agentic RAG is a query enrichment pipeline. When a query is ambiguous, an agent decides how to search. For example, it determines whether “V60 filter” refers to a product or a restaurant, routing the query to the correct search process.
Rank fusion is multi-stage processing. It involves running multiple different searches and then combining, or “stitching,” the results together in a subsequent stage.
The Three Responsibilities of an IR Engineer
These advanced techniques can be derived by focusing on three core responsibilities.

- Predict user intent: What is the most likely representation of what the user is looking for?

- Generate multiple representations (maps): Create different views of the source data ahead of time (document enrichment).

- Match intent to representation: Correctly match the user’s query with the appropriate pre-generated representation.
Practical Application: Curving Space
“Curving space” means shaping data representations and indices to improve search.

For financial documents, one could create multiple “maps” from a single corpus, such as summaries, tables of data, lists of named entities, and form types. This is document enrichment.

Once multiple representations exist, the right indexing strategy must be chosen for each. This involves deciding between semantic search, keyword matching, pre-filters, and whether to use a single index or separate ones.

Sometimes, a second retrieval step, informed by the first, is required. This is a form of staged processing.
Agents as Routers

Agents are transformers in their function: they transform incoming data and instructions into a structured output.

An effective way to use agents is as routers. They take incoming data and route it to different indices or subsequent retrieval stages. This is the core idea behind both Agentic RAG and Multi-Agent RAG.
Representations Must Evolve

A significant danger in RAG is that documents are dynamic. A static embedding will become outdated as the context of a document changes based on new business or world events.

The solution is to design a system that can detect what has changed and re-index only those parts, requiring an architecture built for dynamic updates.
Demo: Semantic Dot Art
To make these concepts concrete, Ayush Chaurasia demonstrated semanticdotart, an application for discovering artworks. The demo shows how a system can serve diverse user intents by creating and searching over multiple representations of the same underlying data.
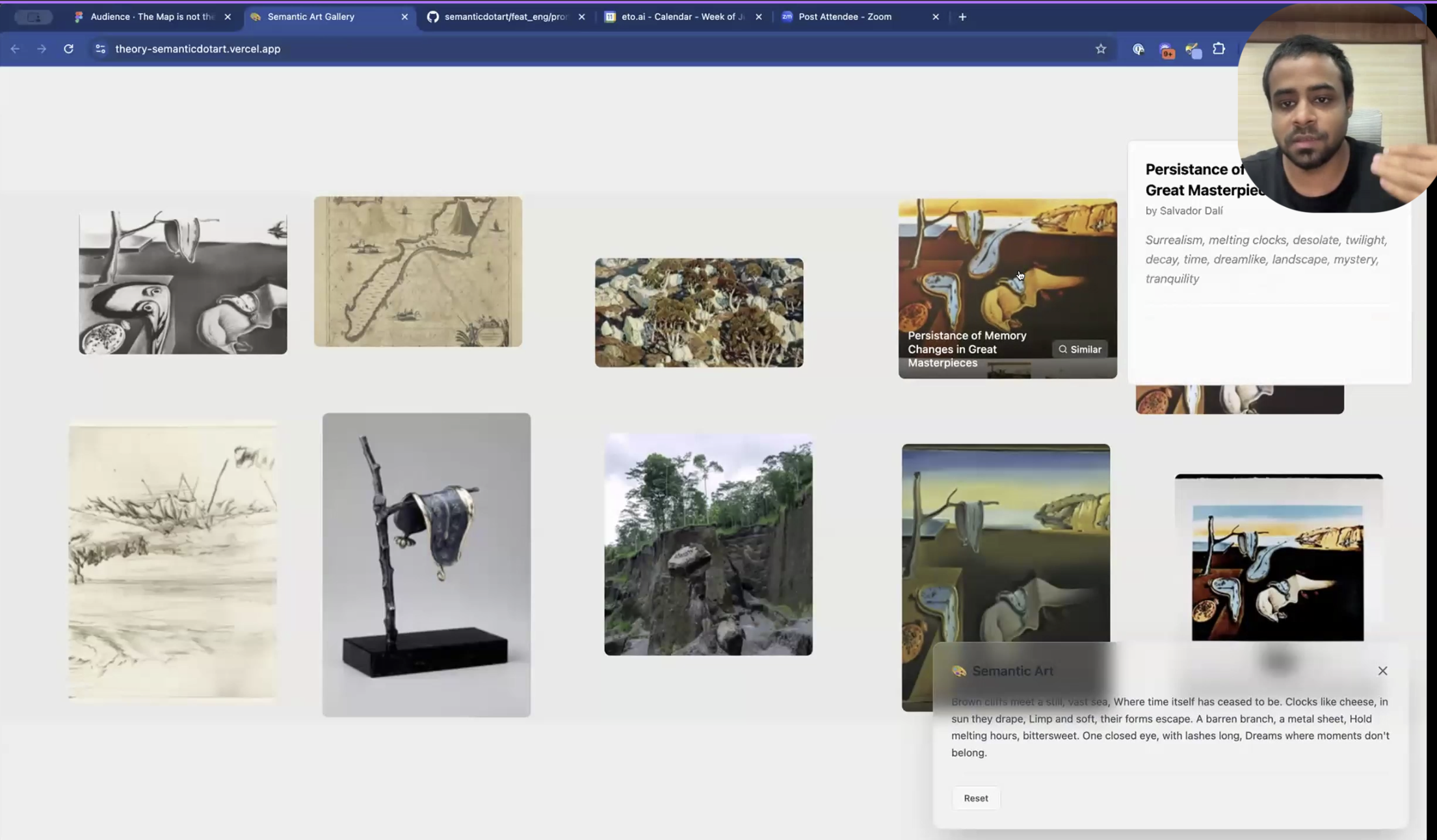
A user can search for art using different “maps” of the data. For example, they can search with a literal description (“multiple clocks melting in a desert”), a poetic description, or even a similar image. The system retrieves not only the original artwork but also derivative pieces and other thematically related works. This is made possible by a rich document enrichment pipeline that creates multiple vector and keyword-based indices for each artwork, capturing everything from mood and style to literal object descriptions.
The retrieval process is agentic. The system routes the user’s query to the most appropriate index or combination of indices. A poetic query might be routed to an index of artistic descriptions, while an image query would use a multimodal embedding. This dynamic routing, combined with multi-stage processing and rank fusion, allows the system to handle a wide variety of user needs and deliver more satisfying, diverse results.
System Diagrams
Ayush then described the system he demoed in more detail.
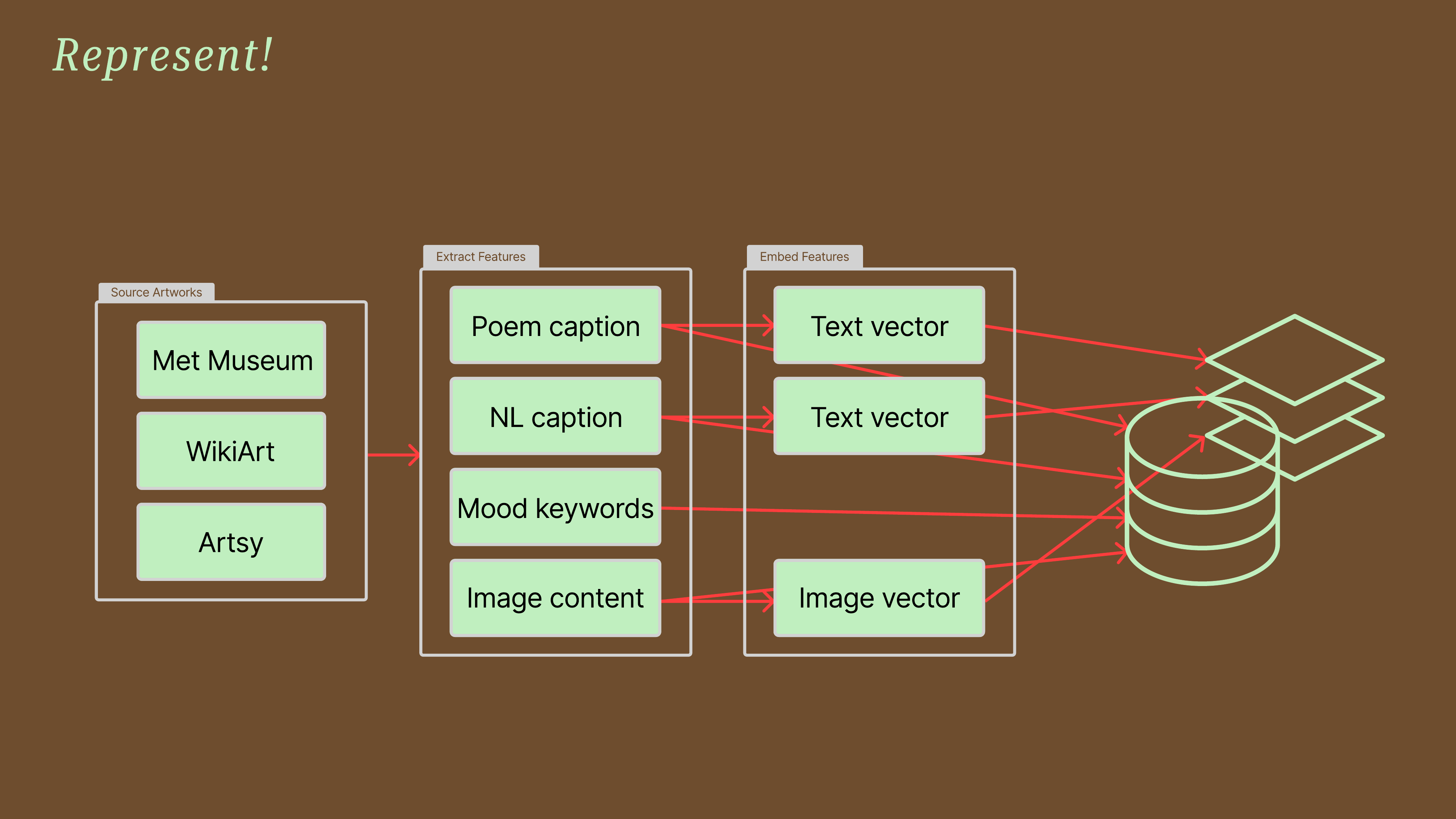
The “Represent!” diagram visualizes the document enrichment pipeline. Data from various sources is processed to extract different features (poem captions, NL captions, mood keywords, image content). These are embedded into different vector types and stored, creating multiple “maps” for the same territory.
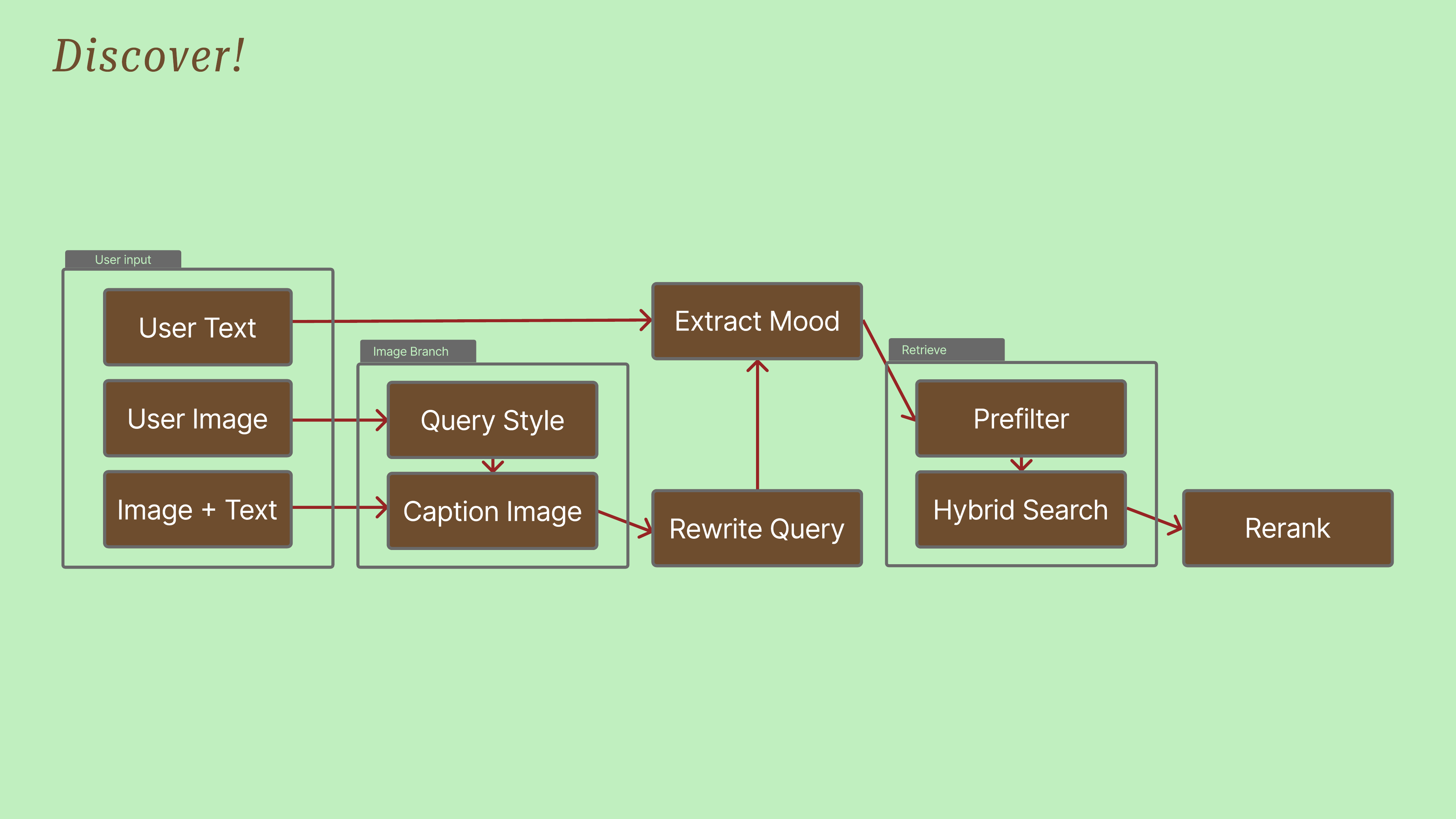
The “Discover!” diagram shows the retrieval pipeline. User input is routed through various stages where it can be enriched (e.g., mood extraction, query rewriting). These enriched queries are then used in a multi-stage retrieval process involving pre-filtering and hybrid search before final reranking.
Q&A Session
Why do people often think there’s only one “map” (representation) for their data? (Timestamp: 32:41) People often seek a single “best” representation. When it fails, the instinct is to fix it rather than augment it with new, different representations. A better mindset for retrieval is to build and use many specialized “maps” of your data, similar to owning different bicycles for different terrains. Modern models make this easier by helping route queries to the correct map.
How do Reasoning Models and Late-Interaction Models (like ColBERT) fit into this “multiple maps” framework? (Timestamp: 35:45) They fit well. Reasoning models are a form of query enrichment, rewriting confusing queries with necessary context. Late-interaction models like ColBERT create diversity within the model itself by generating multiple representations (a vector for each token) for a single document. This creates different “modes” in the latent space for more diverse and nuanced search results.
What is routing in this context, and is it just a classifier? (Timestamp: 42:31) Routing is a retrieval stage where you decide which process or index to use based on the query. For a small number of routes, an LLM can act as a simple classifier (e.g., via a tool call). As the number of routes grows, a dedicated, trained classifier becomes more appropriate. LLMs are good for proving the concept of semantic routing, but for scalable classification, a fine-tuned model is a better approach.
👉 These are the kinds of things we cover in our AI Evals course. You can learn more about the course here. 👈
Video
Here is the full video: