Q: How do I evaluate agentic workflows?
We recommend evaluating agentic workflows in two phases:
1. End-to-end task success. Treat the agent as a black box and ask “did we meet the user’s goal?”. Define a precise success rule per task (exact answer, correct side-effect, etc.) and measure with human or aligned LLM judges. Take note of the first upstream failure when conducting error analysis.
Once error analysis reveals which workflows fail most often, move to step-level diagnostics to understand why they’re failing.
2. Step-level diagnostics. Assuming that you have sufficiently instrumented your system with details of tool calls and responses, you can score individual components such as: - Tool choice: was the selected tool appropriate? - Parameter extraction: were inputs complete and well-formed? - Error handling: did the agent recover from empty results or API failures? - Context retention: did it preserve earlier constraints? - Efficiency: how many steps, seconds, and tokens were spent? - Goal checkpoints: for long workflows verify key milestones.
Example: “Find Berkeley homes under $1M and schedule viewings” breaks into: parameters extracted correctly, relevant listings retrieved, availability checked, and calendar invites sent. Each checkpoint can pass or fail independently, making debugging tractable.
Use transition failure matrices to understand error patterns. Create a matrix where rows represent the last successful state and columns represent where the first failure occurred. This is a great way to understand where the most failures occur.
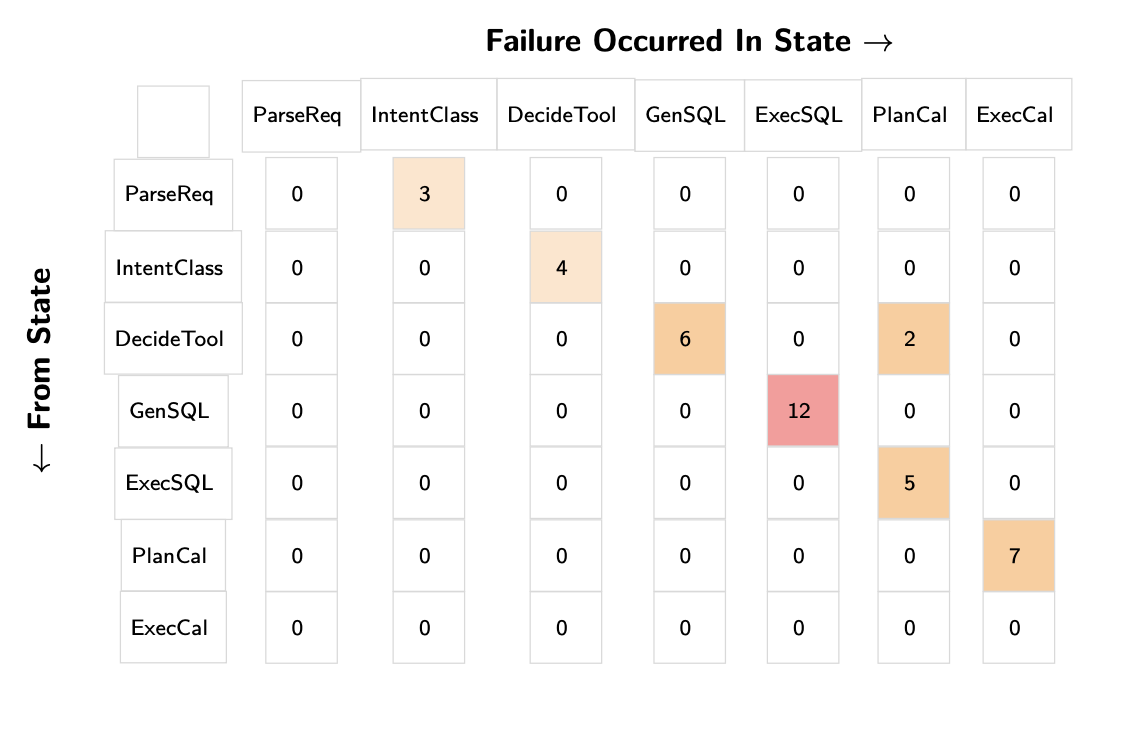
Transition matrices transform overwhelming agent complexity into actionable insights. Instead of drowning in individual trace reviews, you can immediately see that GenSQL → ExecSQL transitions cause 12 failures while DecideTool → PlanCal causes only 2. This data-driven approach guides where to invest debugging effort. Here is another example from Bryan Bischof, that is also a text-to-SQL agent:
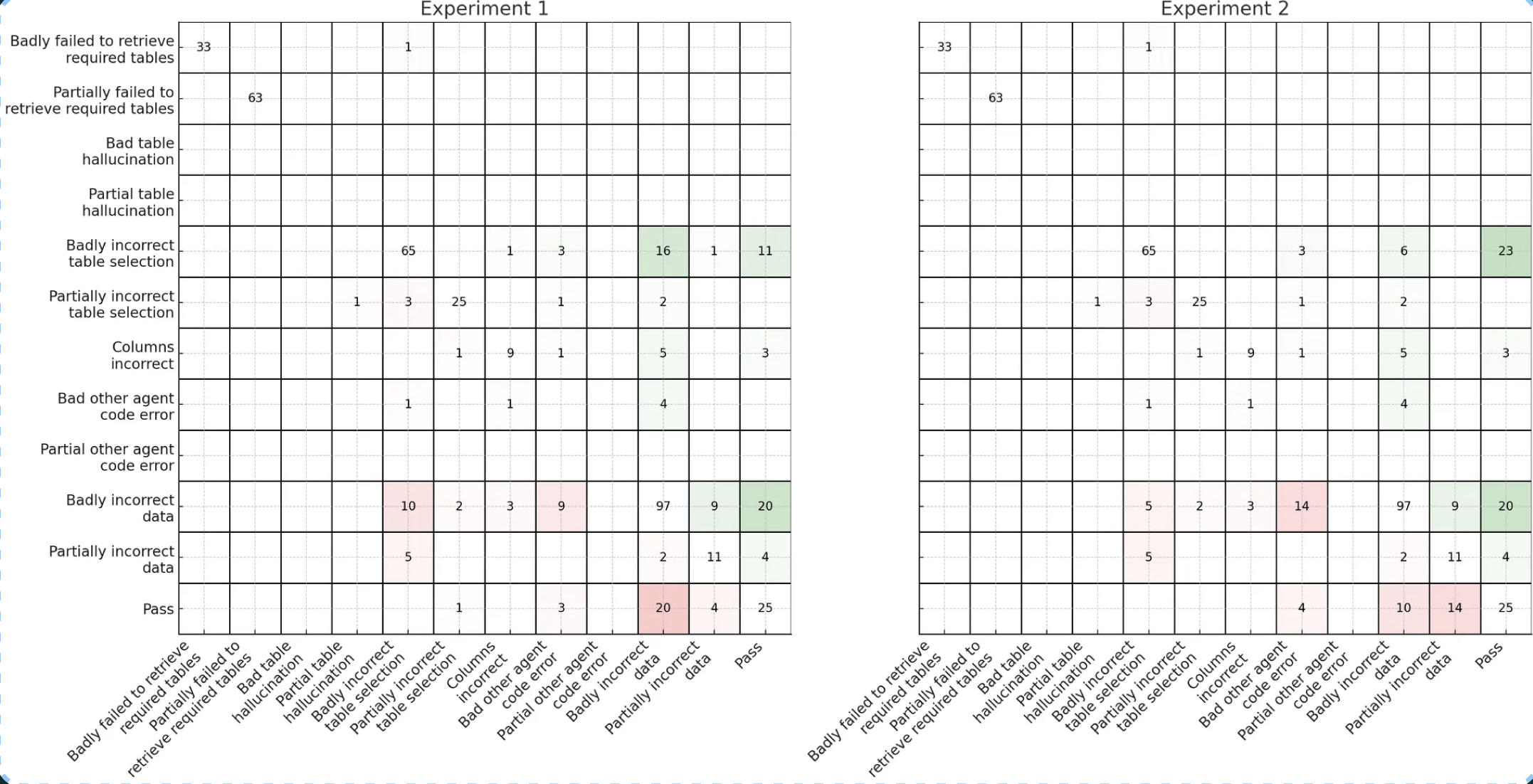
In this example, Bryan shows variation in transition matrices across experiments. How you organize your transition matrix depends on the specifics of your application. For example, Bryan’s text-to-SQL agent has an inherent sequential workflow which he exploits for further analytical insight. You can watch his full talk for more details.
Creating Test Cases for Agent Failures
Creating test cases for agent failures follows the same principles as our previous FAQ on debugging multi-turn conversation traces (i.e. try to reproduce the error in the simplest way possible, only use multi-turn tests when the failure actually requires conversation context, etc.).
This article is part of our AI Evals FAQ, a collection of common questions (and answers) about LLM evaluation. View all FAQs or return to the homepage.