Q: How can I efficiently sample production traces for review?
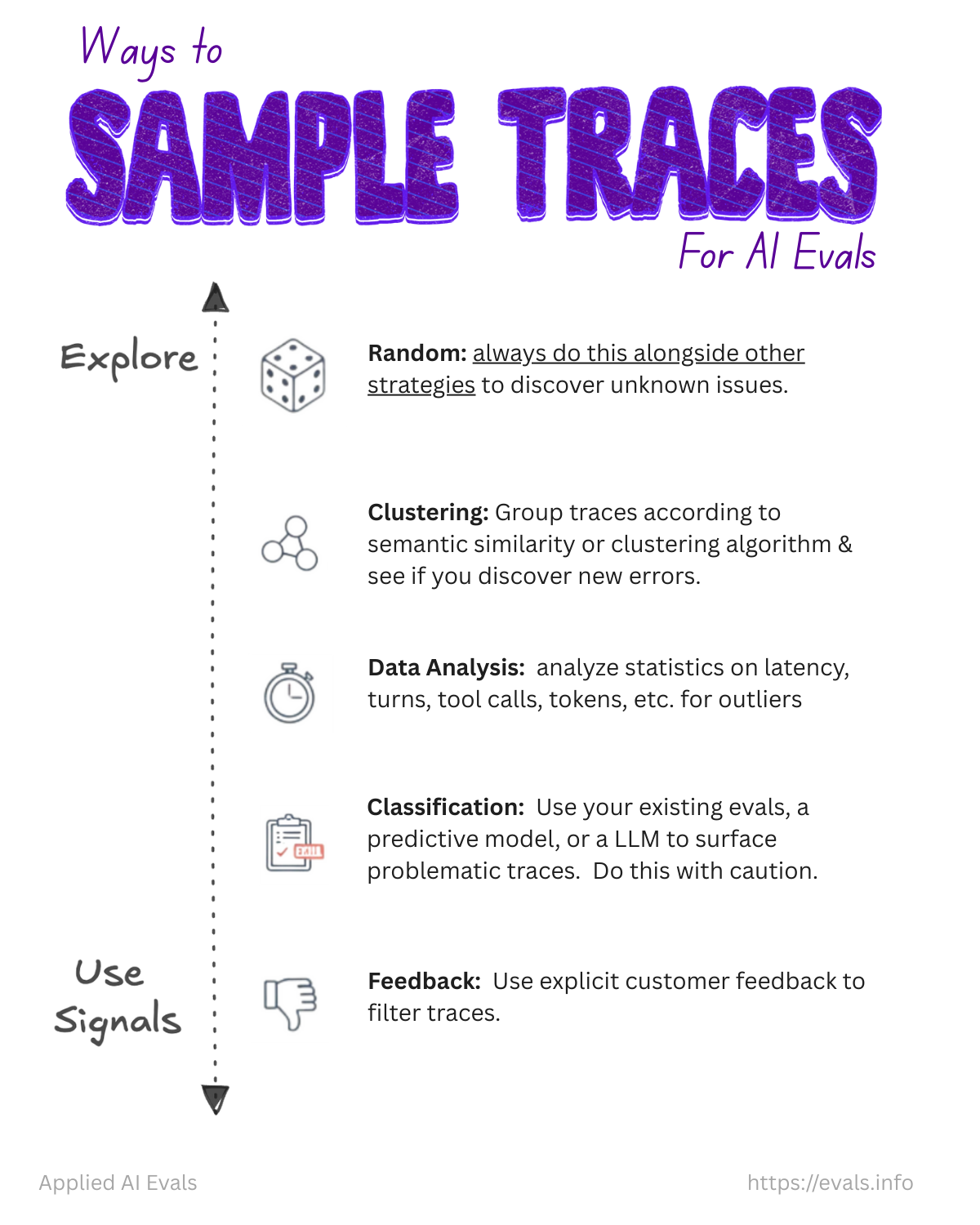
There are many ways to sample production traces for review. Here are some common methods.
| Method | What it does | Main limitation |
|---|---|---|
| Random | Selects traces with equal probability. | A small batch can miss rare cases. |
| Clustering | Groups traces by similar content and selects examples from each group. | The result depends on the features and clustering choices. |
| Data analysis | Reviews extreme values such as latency or tool count. | An extreme value may have nothing to do with quality. |
| Classification | Uses an evaluator or another model to flag likely failures. | It favors problems the classifier already knows how to find. |
| Feedback | Selects traces with negative user feedback. | It misses problems that users do not report. |
The table above orders sampling methods from the most exploratory to the most targeted. When you’re starting out, you should optimize for exploration of the data. As you learn more, you can start to lean more heavily on signals to select traces. The proper mix of methods depends on your goals and requires experimentation.
Keep some random traces in every batch. This gives you a chance to find failure modes that your current signals do not describe.
This flashcard from our evals flashcards series visualizes these methods.
{kind=link}
Use labels to choose the next traces
We can borrow a technique from machine learning called active learning to sample production traces. In active learning, a system asks a person to label the data points that would be most useful for its next update.
In Shreya Shankar’s walkthrough, Claude Code clusters traces and chooses examples from each cluster for review. A monitor command watches annotations.json for new labels. When a label arrives, the agent updates a failure taxonomy and looks for similar cases or different failures.
In the above video, active learning is used in the context of error analysis to find new cases to review. However, this approach can be used anywhere in the workflow where you are annotating data.
This article is part of our AI Evals FAQ, a collection of common questions (and answers) about LLM evaluation. View all FAQs or return to the homepage.