Q: What are LLM Evals?
LLMs
evals
faq
faq-individual
New readers can start with the main guides for product evaluation systems and LLM judges.
If you are completely new to product-specific LLM evals (not foundation model benchmarks), see these posts: part 1, part 2 and part 3. Otherwise, keep reading.
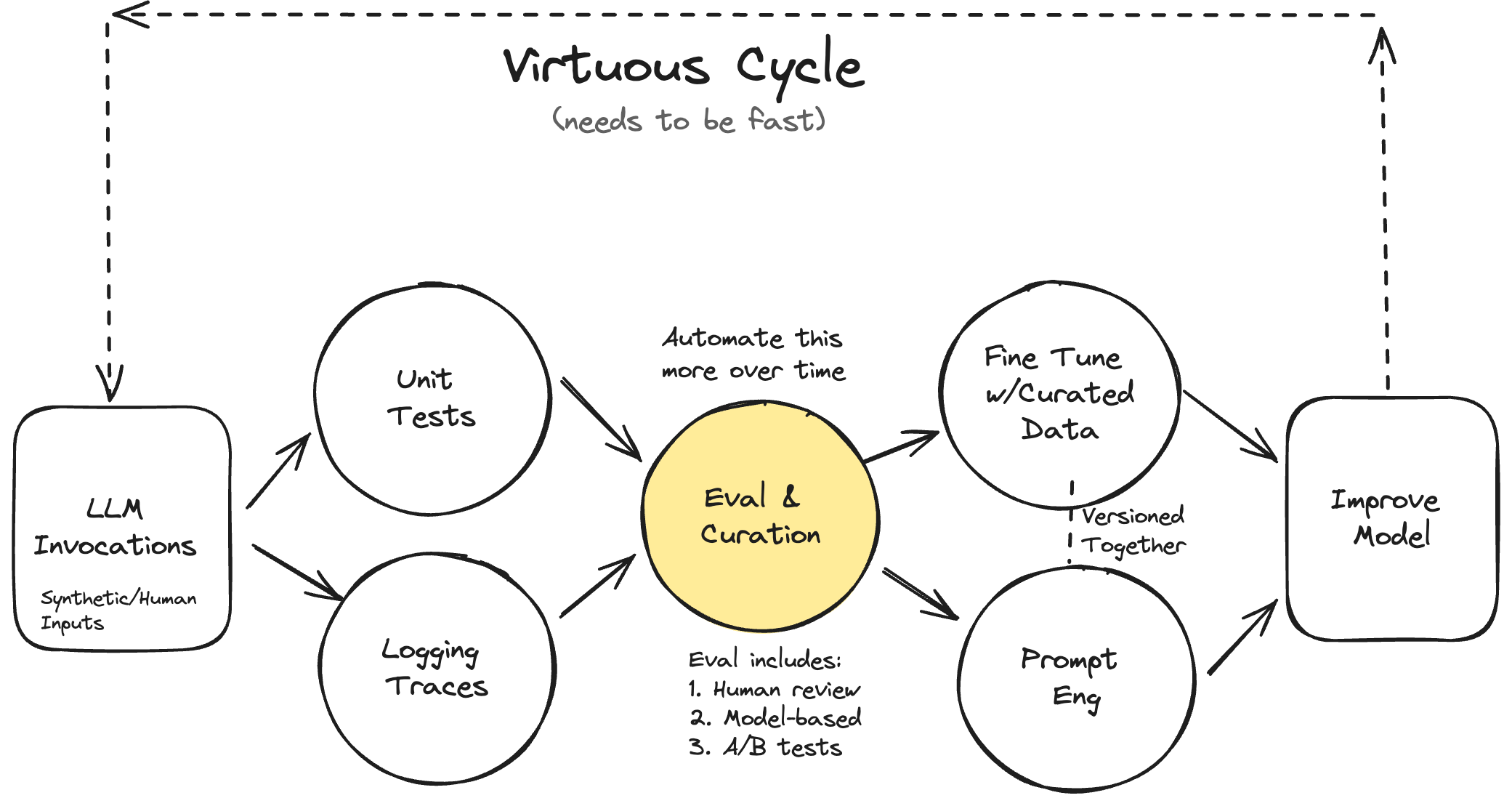
Your AI Product Needs Eval (Evaluation Systems)
Contents:
- Motivation
- Iterating Quickly == Success
- Case Study: Lucy, A Real Estate AI Assistant
- The Types Of Evaluation
- Level 1: Unit Tests
- Level 2: Human & Model Eval
- Level 3: A/B Testing
- Evaluating RAG
- Eval Systems Unlock Superpowers For Free
- Fine-Tuning
- Data Synthesis & Curation
- Debugging
Creating a LLM-as-a-Judge That Drives Business Results
Contents:
- The Problem: AI Teams Are Drowning in Data
- Step 1: Find The Principal Domain Expert
- Step 2: Create a Dataset
- Step 3: Direct The Domain Expert to Make Pass/Fail Judgments with Critiques
- Step 4: Fix Errors
- Step 5: Build Your LLM as A Judge, Iteratively
- Step 6: Perform Error Analysis
- Step 7: Create More Specialized LLM Judges (if needed)
- Recap of Critique Shadowing
- Resources

A Field Guide to Rapidly Improving AI Products
Contents:
- How error analysis consistently reveals the highest-ROI improvements
- Why a simple data viewer is your most important AI investment
- How to empower domain experts (not just engineers) to improve your AI
- Why synthetic data is more effective than you think
- How to maintain trust in your evaluation system
- Why your AI roadmap should count experiments, not features
This article is part of our AI Evals FAQ, a collection of common questions (and answers) about LLM evaluation. View all FAQs or return to the homepage.